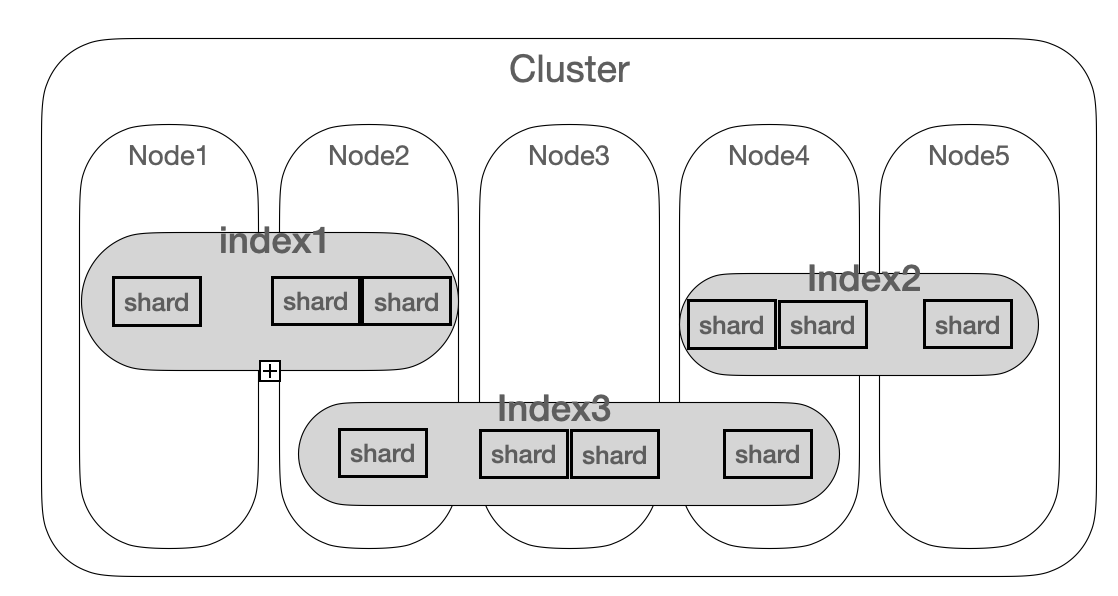
✅ cluster : 엘라스틱에서 가장 큰 유닛
✅ node : 엘라스틱 서치의 인스턴스 (➡️ 메모리 올라가 실행되고 있는 것)
- 운영중에도 노드를 추가/제외할 수 있다는 장점이 있음
- 노드 간의 통신을 함 ➡️ cluster 에 데이터를 넣기 시작하면 데이터가 분산저장됨 ➡️ 노드 간 통신이 되어야함
✅ index : 문서의 집합 / 샤드들의 집합
- 노드 안에 존재
- 인덱스가 노드에 분산되어 저장됨
✅ shard : 실질적인 문서 저장
e.g ) index3에 샤드 4개가 있는데 이 말은 검색엔진 4개가 존재한다는 뜻
이걸 인덱스라는 것에 묶어 분산처리 하도록 만든 것
각각의 샤드가 25% 씩 저장하는 것으로 알아서 4개의 샤드로 분산시켜줌, 4개로 나눠 분산처리하므로 속도⬆️
( 4개의 request 를 보내고 각각 찾아 이를 합쳐 결과로 보냄 )
➡️ ⭐️ 엘라스틱 서치의 핵심 개념
shards
✅ primary shards : original shard, 우리가 넣은 데이터 저장됨, 데이터 인덱싱함
- 한 번 세팅하면 그 뒤로 변경 안됨
- (default) number_of_shards : 1
PUT my_new_index
// index 생성 시
// field 정의는 mapping
// index 관련 설정은 setting
{
"setting" : {
"number_of_shards" : 3
}
}
⚠️ oversharding
- 샤드 하나에 검색엔진(루씬)이 들어가는 것으로 샤드가 많으면 리소스 사용량 ⬆️
- 하나의 샤드에 일반적으로 20~50 GB 사용
e.g ) 내가 수집한 데이터가 100GB 라면 20GB씩 하여 총 5개 정도의 샤드 생성하는 것이 효율적
⚠️ 많은 샤드가 필요한 경우 ➡️ 보통 샤드를 하나 가져가고 인덱스를 여러개 가져가는 것으로 진행
- multiple indices - 인덱스를 여러개 생성
- split API - 해당 API 가지고 샤드 수 늘림
✅ replica shards : primary shard 의 복제본
- 한 번 세팅 후에도 변경 가능
- (default) number_of_replicas : 1
- 노드 하나가 죽어도 문제없도록 여러 노드에 알아서 배치됨
PUT my_new_index
{
"setting" : {
"number_of_replicas" : 2
}
}
✔️ replica 생성 이유
- 장애를 줄일 수 있음 (primary shard가 다운되면 자동으로 replica가 primary로 승격됨)
- 읽기 속도를 높임 (=read throughput)
⭐️ primary와 replica shard 는 같은 노드에 들어가지 않고, 알아서 분산시켜 저장해줌
➡️ 노드를 새로 추가하는 순간 추가된 노드에 샤드를 보내 자동으로 재배치해줌
🔔 검색 속도를 높이는 가이드 (=read throughput, search)
- join이 안되므로 필요한 데이터는 documents 에 다 넣도록 함
- multi_match 보다 copy_to를 사용하여 여러개 합친 걸 한 번에 쿼리하는 것이 좋음
- 필요한 필드한 정확하게 하여 리소스를 줄이도록 함
- 가능하면 keyword 를 많이 사용
- aggs 범위 제한
- filter를 많이 사용하도록 함 (캐시를 쓰므로 속도가 빠름)
🔔 색인 속도를 높이는 가이드 (=indexing, write)
- bulk_API 사용
- 동시에 request 하도록 함
- 내부적으로 인덱싱을 하게되면 검색을 할 때 바로 응답값이 나오도록 하기 위해서 index.refresh_interval 의 시간을 -1로 설정함 (-1을 하면 새로고침 비활성화됨=즉시 검색이 된다는 것)
- 데이터가 많은 경우 replica를 잠깐 disabled 시키고, 데이터 들어온 후 reabled 시키는 것이 좋음 (복제도 리소스 낭비이므로)
- 문서마다 _id(key)가 있는데 유니크하게 줄 수도 있고, 자동으로 생성도 되는데 가능한 자동 생성된 걸 사용하도록 함
'DataBase' 카테고리의 다른 글
| [Elastic Search] Multi cluster operations (CCR,CCS) (0) | 2024.01.10 |
|---|---|
| [Elastic Search] Data Management agenda (ILM,snapshots ...) (1) | 2024.01.09 |
| [Elastic Search] aggregations (metric, bucket, pipeline ...) (0) | 2024.01.06 |
| [Elastic Search] Scripting & Runtime Fields (0) | 2024.01.06 |
| [Elastic Search] Processor / Changing Data (0) | 2024.01.05 |




댓글